
At DeepSource, we strive to run all internal infrastructure and services in High Availability mode. This ensues fault-tolerance, reliability, and resilience in deployments. Our Redis service runs as a three-node HA cluster, with one master, two slaves and a Redis Sentinel process which runs as an auxiliary process to initiate failover. Lately, we have rolled out diskless replication as a feature into production in our Redis cluster deployment, eliminating the need for persistence in Redis master node for replication. Before diving any further, let’s get into some briefing.
Diskless Replication is a feature introduced in Redis in version 2.8.18. Few have implemented it which can be attributed to the inherent fear of breaking down in production deployments.
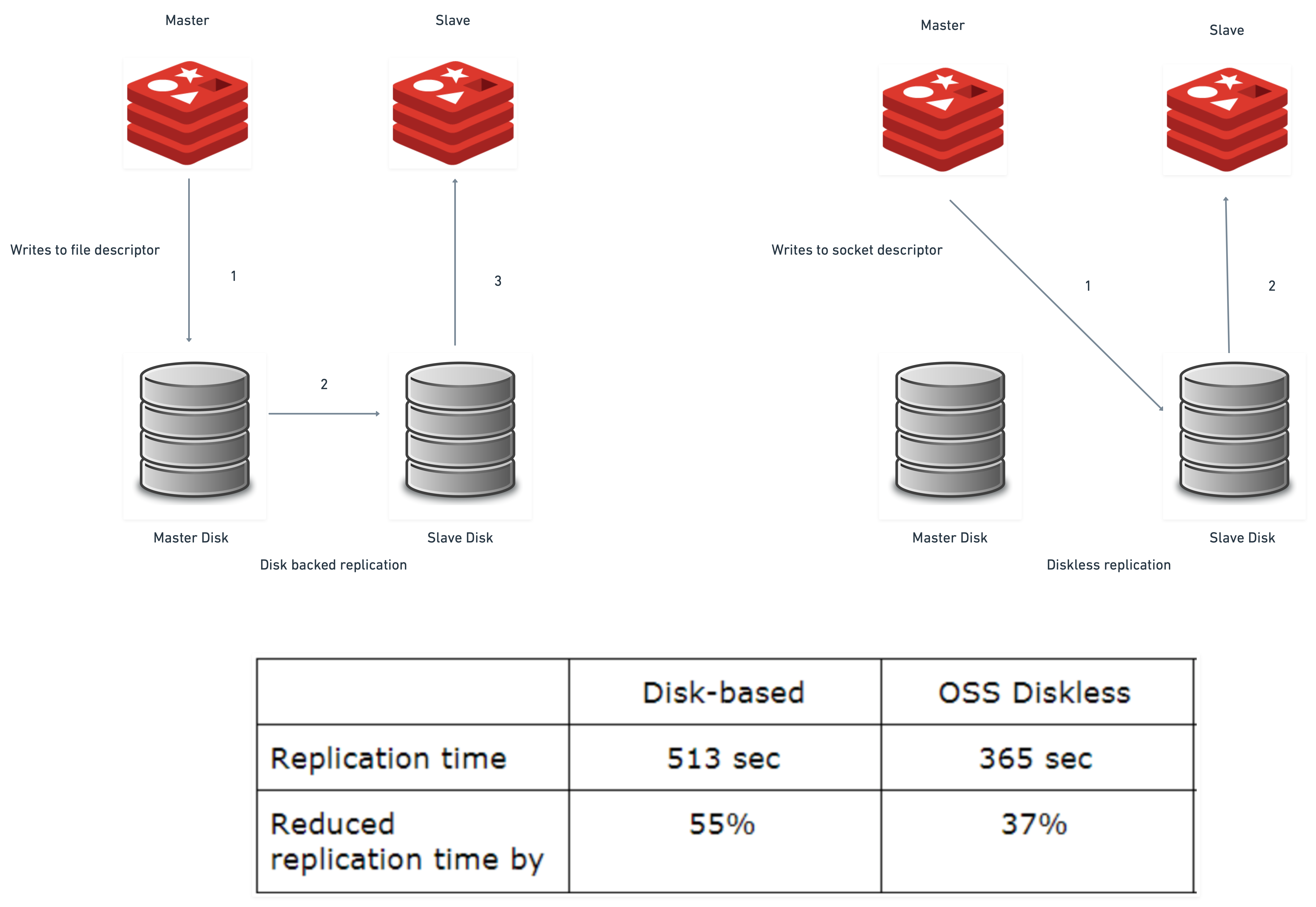
Usually, when a slave breaks down or there is a network fault between the master and the slave, the master attempts to perform a partial resynchronization of the data to the slave. Essentially, the slave reconnects with the master and the replication proceeds incrementally, pulling the differences accumulated so far.
However, when the slave is disconnected for an extended period, or is restarted, or is an entirely new slave, the master needs to perform a full resynchronization. It is a fairly trivial concept, which means to transfer the entire master data set to the slave. The slave flushes the old data set and syncs the new data from scratch. After successful synchronization, successive changes are streamed as normal Redis commands, incrementally, as the master data set itself gets modified because of write commands sent by clients.
The problem arose when bulk transfers were needed to be made during full resynchronizations. A child process is created by the master to generate a Redis Database Backup (RDB) file (analogous to the SQL dump file). After the child process completes the RDB file generation, the file is transferred to the slaves using non-blocking I/O from the parent process. Finally, when the transfer is complete, slaves can reload the RDB file and go online, receiving the incremental stream of new writes.
However, to perform a full resynchronization, the master is required to 1) write data the RDB on disk 2) load back RDB from disk, to send it to slaves
With an improper setup, especially with non-local disks or because of a non-perfect kernel parameter tuning, the disk pressure can lead to latency spikes that are hard to deal with and thus slaves are required to restarted frequently, so it is impossible to avoid a full resynchronization. Thus enters diskless replication.
So what is diskless replication? It is the process of transferring replicated stream of data directly to socket descriptors rather than storing it in the disk and serving it from the disk to the slave instances.
Initially, serving multiple slaves was tricky, since once the RDB transfer initiates, incoming slaves would have to wait for the current child process to finish writing to the current slave and move over to the new incoming slave.
To address this problem, the redis.conf file contains a parameter named repl-diskless-sync-delay. This parameter accepts its value in seconds. It sets a delay to permit incoming slaves to sync with the child process of master for mass resynchronization. This is important since once the transfer starts, it is not possible to serve new replicas arriving, which will be queued for the next RDB transfer, so the server waits for a delay to let more replicas arrive. The delay is specified in seconds, and the default is 5 seconds.
To facilitate this, the I/O code was redesigned to serve a multitude of file descriptors concurrently. Antirez devised the algorithm to resolve the problem. Moreover, in order to parallelize the data transfer even if blocking I/O is being used, the code will try to write a small amount of data to each of the socket descriptors in a loop, so that the kernel sends packets to multiple slaves concurrently.
while(len) {
size_t count = len < 1024 ? len : 1024;
int broken = 0;
for (j = 0; j < r->io.fdset.numfds; j++) {
… error checking removed …
/* Make sure to write 'count' bytes to the socket regardless
* of short writes. */
size_t nwritten = 0;
while(nwritten != count) {
retval = write(r->io.fdset.fds[j],p+nwritten,count-nwritten);
if (retval <= 0) {
… error checkign removed …
}
nwritten += retval;
}
}
p += count;
len -= count;
r->io.fdset.pos += count;
… more error checking removed …
}
Writing to file descriptors isn’t just the only dimension to this problem. A big chunk of it lies in actually handling a bunch of slaves without actually requiring to block the process for other incoming slaves.
However, when the RDB is terminated, the child needs to perform feedback of slaves which have received the RDB and can continue with the replication streaming process. The child process returns an array of slave IDs and their associated error states, thus enabling the parent process to log the error states of the slaves.
The apparent problem with diskless replication is that writing to disks differs from writing to sockets. * The API is different since the Redis Database Backup code conventionally writes to C file pointers while our situation demands writing to sockets, which is basically writing to socket descriptors. * Disk writes primarily don’t tend to fail, if not for super hard I/O errors (if the disk is full and so on). For sockets though, it’s a different ball game altogether, since writes can get delayed as the receiver could get slow and the local kernel buffer could get full. * The problem of timeouts is ever expanding in the realm of sockets. What if the receiving end fails to receive packets due to a breakdown, or just the TCP connection is dead.
According to Salvatore Sanfilippo (aka antirez), the author of Redis, there were two options in front of him to mitigate the issue. * generate the RDB file inside memory and then perform the transfer. * write to the sockets directly and incrementally, as the RDB is being generated.
Way 1 was riskier as it had the overhead of too much memory consumption. The feature had to be targeted for environments with slow disks, but with faster networks and higher bandwidths, without consuming too much memory. Hence way 2 was selected.
The idea of replication without persistence is definitely overwhelming and intimidating, but Redis just made it through. Supporting replication in a non-disk replication removes undesirable storage moving parts, and as we are all aware of the fact that disk I/Os are slow and sluggish. Implementing this in our Kubernetes ecosystem has made significant improvements in I/O and caching metrics and has made our Redis deployments leaner and meaner.

